基于TSM的高空抛物识别系统
模型选择
| 特性 | YOLO (目标检测) | TSM (动作识别) |
|---|---|---|
| 输入单元 | 单张图片 (.jpg) | 视频片段 (.mp4 / 帧序列) |
| 标签文件 | 坐标框 (txt/xml) | 类别 ID (0 或 1) |
| 难点 | 小目标检测、重叠遮挡 | 采样频率、动作起始点定位 |
| 本项目应用 | 识别“这是个瓶子” | 识别“瓶子正在坠落” |
OpenMMLab (MMAction2) 框架,搭配 TSM 模型。
TSM(Temporal Shift Module)简介
一句话定义
TSM 是一种轻量级视频理解模型,通过在时间维度上"移动"特征来捕捉动作信息,几乎不增加计算量。
核心原理
普通 CNN 处理图片时,每一帧是独立的——它不知道前一帧和后一帧发生了什么。
TSM 的做法很简单:把特征图在时间维度上移一下。
时间步: t-1 t t+1
通道1: ←───── ─────
通道2: ───── ─────→
通道3: 不动 不动 不动
- 一部分通道向前看一帧
- 一部分通道向后看一帧
- 一部分通道不动
这样模型在处理第 t 帧时,天然就能"感知"到 t-1 和 t+1 帧的信息,从而理解运动方向和速度。
为什么适合高空抛物
| 特性 | 单帧检测(YOLO) | TSM(视频理解) |
|---|---|---|
| 输入 | 1 张图片 | 8 帧连续画面 |
| 能识别 | “有个瓶子” | “瓶子在往下掉” |
| 计算量 | 低 | 和单帧几乎一样 |
高空抛物的关键不是"有什么东西",而是"这个东西在运动"。TSM 能捕捉这种时序变化,而且计算量几乎没有增加。
和其他视频模型的对比
| 模型 | 速度 | 精度 | 特点 |
|---|---|---|---|
| TSM | ⚡ 快 | 高 | 移动特征,零额外计算 |
| 3D CNN (SlowFast) | 🐌 慢 | 很高 | 用 3D 卷积,计算量大 |
| Video Transformer | 🐌 很慢 | 最高 | 注意力机制,需要大量数据 |
TSM 是速度和精度的最佳平衡,特别适合小样本场景。
在项目中的应用
- 模型:TSM + ResNet50 骨干网络
- 输入:每个视频切 8 帧(1x1x8 采样策略)
- 预训练:Kinetics-400(40 万段视频、400 个动作类别)
- 微调:冻结前 4 层,只训练最后的分类头
一句话总结
TSM 就像给模型加了一个"时间感知器",让它在看每一帧画面时,能同时看到前后几帧的变化,从而判断出"物体在坠落"这个动作。
环境配置

#指定清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 1. 安装基础工具
pip install openmim
pip install "requests>=2.31"
# 2. 安装锁死版本的核心依赖(NumPy 1.x、旧版 OpenCV、MoviePy 1.x、降级版 Requests)
pip install "numpy<2.0.0" "opencv-python==4.9.0.80" "opencv-contrib-python==4.9.0.80" "moviepy<2.0.0" "requests==2.28.2"
# 3. 安装与 MMAction2 (1.x架构) 完美匹配的 MMCV
mim install "mmcv-full<2.0.0"
# 4. 下载并安装 MMAction2
cd /project/train/src_repo/ # 进入你的代码目录
git clone https://gitee.com/open-mmlab/mmaction2.git # 使用 Gitee 国内源下载更快
cd mmaction2
pip install -v -e . # 安装
权重下载
# 这行命令的意思是:帮我自动下载 tsm_r50_video... 这个模型对应的最新权重,并保存在当前目录(--dest .)
mim download mmaction2 --config tsm_r50_video_1x1x8_50e_kinetics400_rgb --dest .
执行之后将.pth的权重名改成ResNet50,删除对应的py文件即可
进入样例数据集查看是否存在
cd /home/data
ll

这个2623就是存放样例数据集的地方,将2623里的内容展开得到一段mp4视频文件和json
这个 JSON 文件就是告诉视频里到底哪里有高空抛物
打开json文件

只告诉了“抛物”发生在哪个时间段
数据预处理
在/project/src_repo目录下创建prepare_data.py
import json
import os
import random
import traceback
from moviepy.editor import VideoFileClip
# ================= 配置路径 =================
SOURCE_DIR = '/home/data/2623'
OUTPUT_DIR = '/project/train/src_repo/dataset_tsm'
CLIP_DURATION = 2.0 # 固定 2 秒
os.makedirs(os.path.join(OUTPUT_DIR, 'videos'), exist_ok=True)
train_txt = open(os.path.join(OUTPUT_DIR, 'train.txt'), 'w')
val_txt = open(os.path.join(OUTPUT_DIR, 'val.txt'), 'w')
with open(os.path.join(SOURCE_DIR, 'label.json'), 'r') as f:
label_data = json.load(f)
videos_dict = label_data.get("videos", {})
video_names = list(videos_dict.keys())
random.shuffle(video_names)
split_idx = int(len(video_names) * 0.8)
train_vids = set(video_names[:split_idx])
total_clips = 0
success_videos = 0
print(f"⏳ 找到 {len(video_names)} 个视频记录,准备开始切片...")
for video_name, segments_info in videos_dict.items():
# 修复可能的后缀重复问题
v_name_clean = video_name.replace('.mp4', '')
video_path = os.path.join(SOURCE_DIR, f"{v_name_clean}.mp4")
if not os.path.exists(video_path):
print(f"⚠️ 找不到文件: {video_path}")
continue
try:
clip = VideoFileClip(video_path)
video_length = clip.duration
except Exception as e:
print(f"❌ 读取视频 {video_name} 失败,报错信息:\n{e}")
continue
split = 'train' if video_name in train_vids else 'val'
txt_file = train_txt if split == 'train' else val_txt
fall_ranges = [s.get("segment") for s in segments_info if s.get("label") == "the_fall_path_determined"]
# 1. 提取正样本 (加入时间轴滑动增强,1个动作变3个样本)
for idx, (start, end) in enumerate(fall_ranges):
# 偏移量:稍微提前0.5秒,恰好从0开始,稍微滞后0.2秒
offsets = [-0.5, 0.0, 0.2]
for j, offset in enumerate(offsets):
clip_start = max(0, start + offset)
clip_end = min(video_length, clip_start + CLIP_DURATION)
# 如果截出来的不足 1 秒,跳过(防止过短的边角料)
if clip_end - clip_start < 1.0:
continue
save_name = f"{v_name_clean}_fall_{idx}_aug{j}.mp4"
save_path = os.path.join(OUTPUT_DIR, 'videos', save_name)
try:
subclip = clip.subclip(clip_start, clip_end)
subclip.write_videofile(save_path, audio=False, logger=None)
txt_file.write(f"{save_path} 1\n")
total_clips += 1
except Exception as e:
print(f"⚠️ 切片 {save_name} 失败: {e}")
# 2. 提取负样本 (适当增加负样本比例)
for i in range(4): # 增加到 4 个负样本
rand_start = random.uniform(0, max(0, video_length - CLIP_DURATION))
is_safe = True
for (f_start, f_end) in fall_ranges:
# 严格避开抛物时间段(前后各留 1 秒缓冲)
if not (rand_start + CLIP_DURATION < f_start - 1.0 or rand_start > f_end + 1.0):
is_safe = False
break
if is_safe:
save_name = f"{v_name_clean}_normal_{i}.mp4"
save_path = os.path.join(OUTPUT_DIR, 'videos', save_name)
try:
subclip = clip.subclip(rand_start, rand_start + CLIP_DURATION)
subclip.write_videofile(save_path, audio=False, logger=None)
txt_file.write(f"{save_path} 0\n")
total_clips += 1
except:
pass
clip.close()
success_videos += 1
train_txt.close()
val_txt.close()
print(f"\n🎉 大功告成!成功处理了 {success_videos} 个视频,共生成了 {total_clips} 个短视频片段。")
成功生成了dataset_tsm文件
将样例集分为正样本(抛物片段)和负样本(对应json文件里的无抛物片段)
这里因为样例集只有一段视频和标注,所以使用同样的正样本和负样本
编写训练脚本
打开对应的模型自带的数据处理文件
/project/train/src_repo/mmaction2/configs/recognition/tsm/tsm_r50_video_inference_1x1x8_100e_kinetics400_rgb.py
全选粘贴以下代码
_base_ = [
'../../_base_/models/tsm_r50.py',
'../../_base_/schedules/sgd_tsm_50e.py',
'../../_base_/default_runtime.py'
]
# =====================================================
# 1. 模型配置:微调策略 (2分类 + 重度防过拟合)
# =====================================================
model = dict(
backbone=dict(
pretrained=None, # 统一使用最下方的 load_from 加载权重
frozen_stages=3, # # 【修改】:从 4 改为 3,释放出 ResNet 的最后一层来学习抛物特征
norm_eval=True # 【关键】将 BN 层的均值和方差锁死在评估模式,防止小 Batch 训练导致剧烈抖动
),
cls_head=dict(
num_classes=2,
dropout_ratio=0.6 # 【修改】:从 0.8 降到 0.6,允许更多神经元参与判断
)
)
# =====================================================
# 2. 数据集路径设置
# =====================================================
dataset_type = 'VideoDataset'
data_root = ''
data_root_val = ''
ann_file_train = '/project/train/src_repo/dataset_tsm/train.txt'
ann_file_val = '/project/train/src_repo/dataset_tsm/val.txt'
ann_file_test = '/project/train/src_repo/dataset_tsm/val.txt'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
# =====================================================
# 3. 数据流水线 (Data Pipeline)
# =====================================================
train_pipeline = [
dict(type='DecordInit'),
dict(type='SampleFrames', clip_len=1, frame_interval=1, num_clips=8),
dict(type='DecordDecode'),
dict(type='Resize', scale=(-1, 256)),
# 【关键新增】:颜色抖动。让同一个切片在不同轮次呈现不同的亮度/对比度,防止模型记住特定光线
dict(type='ColorJitter', brightness=0.2, contrast=0.2, saturation=0.2),
dict(type='MultiScaleCrop', input_size=224, scales=(1, 0.875, 0.75, 0.66),
random_crop=False, max_wh_scale_gap=1, num_fixed_crops=13),
dict(type='Resize', scale=(224, 224), keep_ratio=False),
dict(type='Flip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCHW'),
dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['imgs', 'label'])
]
val_pipeline = [
dict(type='DecordInit'),
dict(type='SampleFrames', clip_len=1, frame_interval=1, num_clips=8, test_mode=True),
dict(type='DecordDecode'),
dict(type='Resize', scale=(-1, 256)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCHW'),
dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['imgs'])
]
# =====================================================
# 4. 数据装载与评估机制
# =====================================================
data = dict(
videos_per_gpu=8,
workers_per_gpu=4,
train=dict(type=dataset_type, ann_file=ann_file_train, data_prefix=data_root, pipeline=train_pipeline),
val=dict(type=dataset_type, ann_file=ann_file_val, data_prefix=data_root_val, pipeline=val_pipeline),
test=dict(type=dataset_type, ann_file=ann_file_test, data_prefix=data_root_val, pipeline=val_pipeline)
)
# 【关键修改】:每 2 轮跑一次验证,并自动保存 val 准确率最高的权重
evaluation = dict(
interval=5,
metrics=['top_k_accuracy', 'mean_class_accuracy'],
save_best='top1_acc'
)
# =====================================================
# 5. 训练策略与日志记录
# =====================================================
# 【关键修改】:学习率降低到 0.0005,因为是基于 Kinetics 的微调
optimizer = dict(type='SGD', lr=0.0005, momentum=0.9, weight_decay=0.0001)
# 学习率衰减策略(如果总 epoch 较短,可以适当提前衰减)
lr_config = dict(policy='step', step=[20, 40])
total_epochs = 50
checkpoint_config = dict(interval=5)
work_dir = '/project/train/models/work_dirs/tsm_r50_video_2d_1x1x8_50e_kinetics400_rgb/'
# 强制日志每 1 步就打印一次 Loss
log_config = dict(interval=1, hooks=[dict(type='TextLoggerHook')])
# =====================================================
# 6. 显卡设备与预训练权重加载
# =====================================================
# 确保这里指向你刚刚下载好的 Kinetics-400 的 TSM 权重文件
load_from = '/project/train/src_repo/tsm.pth'
gpu_ids = [0]
device = 'cuda'
复盘一下我们在这 63 个高空抛物视频(极小样本)任务上,为了跑通并达到最佳效果,从头到尾做了哪些关键修改。
整体可以概括为两大部分:数据处理流水线的重构 和 模型微调策略的防过拟合强化。
第一部分:数据处理与扩增(解决“没有数据”的问题)
- 修复异常截断 (Bug Fix):
- 之前: 使用
try...except...continue默默吞掉了moviepy在云端环境解帧时的所有报错。 - 修改: 增加了完整的报错捕获和日志打印,确保文件能被正确读取,同时修复了可能导致
.mp4后缀重复拼接的路径问题。
- 之前: 使用
- 引入时间轴抖动增强 (Temporal Jittering):
- 之前: 1 次抛物动作只死板地切出 1 个正样本。63 个视频最多只能产出几十个正样本,严重不足。
- 修改: 针对同一次抛物动作,分别在动作起始时间
[-0.5秒, 0.0秒, +0.2秒]处进行滑动切割。将 1 个动作裂变为了 3 个正样本,直接将正样本数量翻了三倍。
- 增加负样本比例:
- 之前: 每个视频随机取 3 个正常片段(背景)。
- 修改: 增加到了 4 个,并在切割时严格判断,确保选取的“背景时间段”距离抛物动作至少有 1 秒的安全缓冲,防止切到模棱两可的片段。
第二部分:微调策略与正则化(解决“过度记忆”的问题)
在只有几百个短视频切片的情况下,2400 万参数的 ResNet50 极其容易在几轮内就“背下”这几百个视频的背景(比如某栋楼的特定窗户),而不是真正学会看“物体掉落”。
在 MMAction2 的配置文件 (tsm_r50_...py) 中,我们做了以下四大调整:
- 引入强大的先验知识 (Kinetics 预训练):
- 之前: 加载的是
torchvision://resnet50(ImageNet 图片权重),模型天生缺乏理解时间序列(动作)的能力。 - 修改: 替换为官方在 Kinetics-400 大规模视频数据集上训练好的 TSM 权重,相当于找了一个已经看过几十万个动作视频的“老手”来学抛物。
- 之前: 加载的是
- 锁死特征提取器 (冻结 Backbone):
- 修改: 在
backbone中加入frozen_stages=4和norm_eval=True。这强迫模型绝对不准修改底层的特征提取网络,只允许用最后的全连接层(cls_head)来做二分类判断。这是小样本微调最核心的保命手段。
- 修改: 在
- 实施极端正则化 (超高 Dropout):
- 之前:
dropout_ratio=0.5(常规值)。 - 修改: 提高到 dropout_ratio=0.8。每次训练前向传播时,随机“屏蔽”掉 80% 的特征连接。这种极其恶劣的学习环境,强迫模型不能依赖任何单一的图像特征,必须找到最本质的抛物线规律。
- 之前:
- 降低学习率与增加颜色扰动:
- 修改: 将学习率
lr从0.005大幅降低到 0.0005,因为我们是在做精细微调,步子不能大。 - 修改: 在
train_pipeline中加入了 ColorJitter(颜色抖动),每次读取同一段视频时,都随机改变它的亮度、对比度和饱和度,让模型难以通过记住光照环境来偷懒。
- 修改: 将学习率
回到终端,在/project/train/src_repo目录下编写run.sh
#!/bin/bash
# run.sh
WORK_DIR="/project/train/models/work_dirs/tsm_r50_video_2d_1x1x8_50e_kinetics400_rgb"
# 1. 在训练开始前手动清理,这只会在你运行脚本时执行一次
if [ -d "$WORK_DIR" ]; then
echo "清理旧的训练数据..."
rm -rf "$WORK_DIR"
fi
# 2. 启动训练
python /project/train/src_repo/mmaction2/tools/train.py /project/train/src_repo/mmaction2/configs/recognition/tsm/tsm_r50_video_1x1x8_50e_kinetics400_rgb.py
# 3. 生成 Loss 曲线并保存到该目录
python /project/train/src_repo/mmaction2/tools/analysis/analyze_logs.py plot_curve $(ls -t ${WORK_DIR}/*.log.json | head -n 1) --keys loss --legend loss --out ${WORK_DIR}/loss_curve.png
# 4. 生成 准确率 曲线并保存到该目录
python /project/train/src_repo/mmaction2/tools/analysis/analyze_logs.py plot_curve $(ls -t ${WORK_DIR}/*.log.json | head -n 1) --keys top1_acc --legend accuracy --out ${WORK_DIR}/accuracy_curve.png
运行脚本
bash /project/train/src_repo/run.sh
运行完成并生成相应的训练结果图:
这里由于训练集只有1个视频,切分完后训练的效果也不太好
画出 Loss 曲线(损失函数)和画出 Accuracy 曲线(准确率)
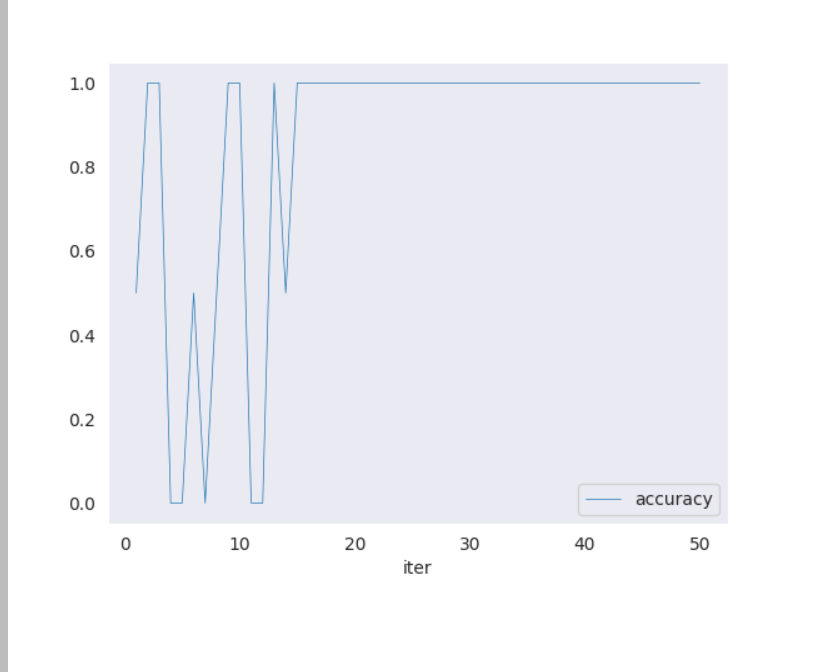
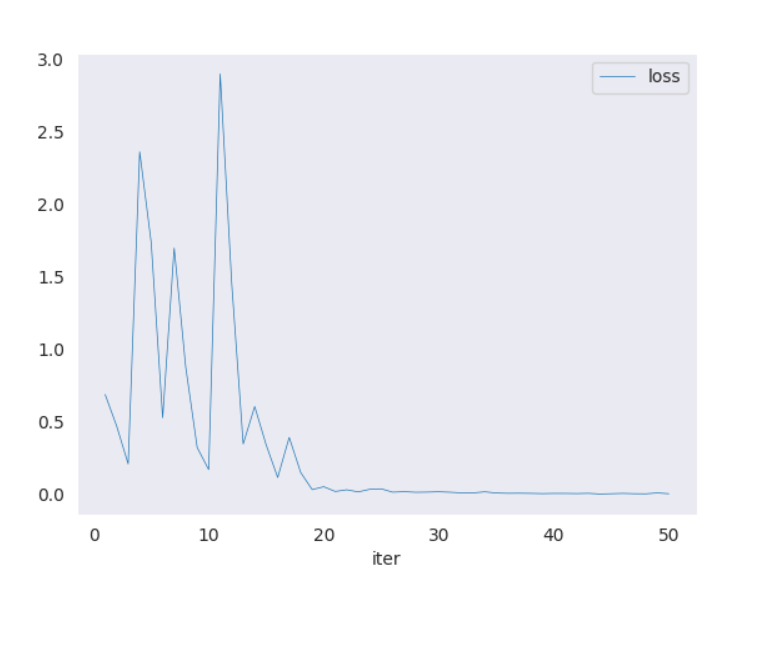
编写测试脚本
在/project/ev_sdk/src目录下创建ji.py文件
import json
import os
import cv2
import numpy as np
from mmaction.apis import init_recognizer, inference_recognizer
# =================配置区域=================
# 请确保这些路径在你的平台环境中是正确的
CONFIG_FILE = '/project/train/src_repo/mmaction2/configs/recognition/tsm/tsm_r50_video_1x1x8_50e_kinetics400_rgb.py'
CHECKPOINT_FILE = '/project/train/models/work_dirs/tsm_r50_video_2d_1x1x8_50e_kinetics400_rgb/latest.pth' # 平台通常会把模型放在这个位置
# ==========================================
def init():
"""
平台初始化时调用,加载模型并常驻显存
"""
# 如果平台路径不固定,可以尝试使用相对路径
model = init_recognizer(CONFIG_FILE, CHECKPOINT_FILE, device='cuda:0')
return model
def process_video(net, input_video, args=None):
"""
平台测试每个视频时调用
net: 就是 init() 返回的 model
input_video: 测试视频的绝对路径
"""
# 1. 使用 MMAction2 官方 API 进行推理
# results 是一个列表 [prob_0, prob_1],对应 [正常, 抛物]
results = inference_recognizer(net, input_video)
# 2. 解析分类结果
# 判定索引 (0: normal, 1: fall)
# 使用 .item() 或者 [0] 来提取元组/数组里的纯数字
is_fall = 1 if np.mean(results[1]) > np.mean(results[0]) else 0
score = float(np.mean(results[is_fall]))
label_name = "the_fall_path_determined" if is_fall == 1 else "normal"
# 3. 获取视频时长 (用于填充要求的 segment 字段)
cap = cv2.VideoCapture(input_video)
fps = cap.get(cv2.CAP_PROP_FPS)
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
duration = frame_count / fps if fps > 0 else 0
cap.release()
# 4. 按照平台要求的 JSON 格式组装输出
# 这里的 video_name 平台通常要求不带后缀
video_id = os.path.splitext(os.path.basename(input_video))[0]
output = {
'model_data': {
'video_name': video_id,
'objects': [
{
'label': label_name,
'score': round(score, 4),
'segment': [0, round(duration, 2)] # TSM是对全视频分类,所以填 0 到结束
}
]
}
}
return json.dumps(output)
# ... 你之前的 init 和 process_video 函数保持不变 ...
if __name__ == '__main__':
# ================= 调试配置区 =================
# 请指定一个你编码环境中真实存在的测试视频路径
TEST_VIDEO_PATH = '/project/train/src_repo/dataset_tsm/videos/parabolic20230825_259_fall_0.mp4'
# =============================================
print("🔍 正在初始化模型...")
try:
# 1. 调用 init 加载模型
recognizer = init()
print("✅ 模型加载成功!")
# 2. 检查视频文件是否存在
if not os.path.exists(TEST_VIDEO_PATH):
print(f"❌ 找不到测试视频: {TEST_VIDEO_PATH}")
else:
print(f"🚀 开始推理视频: {TEST_VIDEO_PATH}")
# 3. 调用推理函数
# 注意:process_video 返回的是 JSON 字符串
json_result = process_video(recognizer, TEST_VIDEO_PATH)
# 4. 格式化打印结果,方便观察
result_dict = json.loads(json_result)
print("\n--- 推理结果预览 ---")
print(json.dumps(result_dict, indent=4, ensure_ascii=False))
# 简单的结果逻辑验证
obj = result_dict['model_data']['objects'][0]
print(f"\n📢 结论: 模型认为该视频是 [{obj['label']}],置信度为 {obj['score']}")
except Exception as e:
print(f"💥 运行过程中发生错误: {str(e)}")
接着运行测试脚本
python ji.py
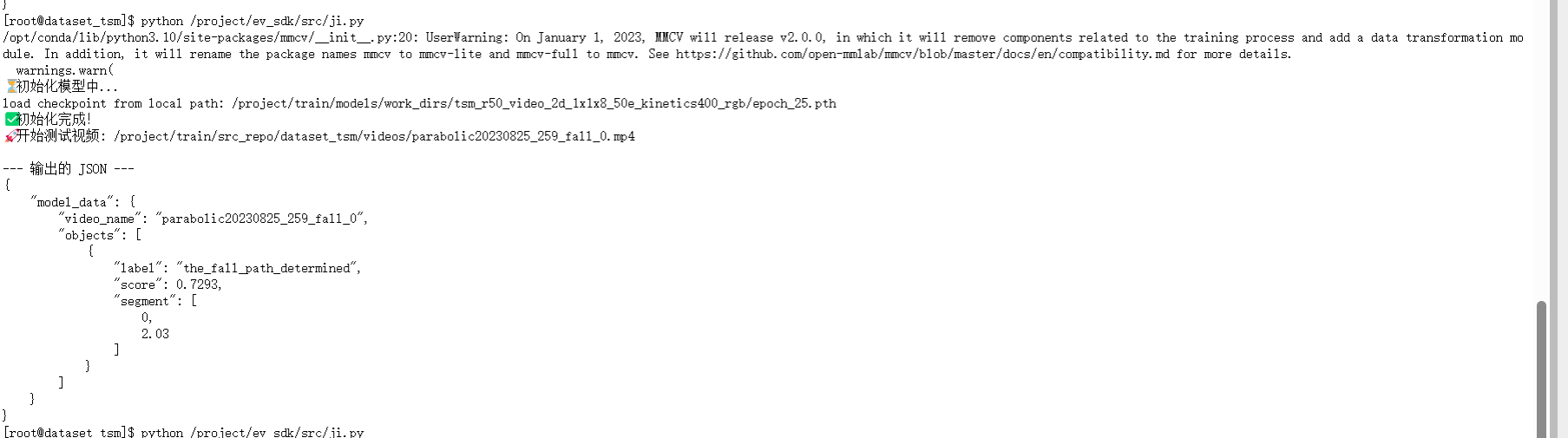
这里置信度为0.72